Video inpainting is the task of filling a region in a video in a visually convincing manner. It is very challenging due to the high dimensionality of the data and the temporal consistency required for obtaining convincing results. Recently, diffusion models have shown impressive results in modeling complex data distributions, including images and videos.
Such models remain nonetheless very expensive to train and to perform inference with, which strongly
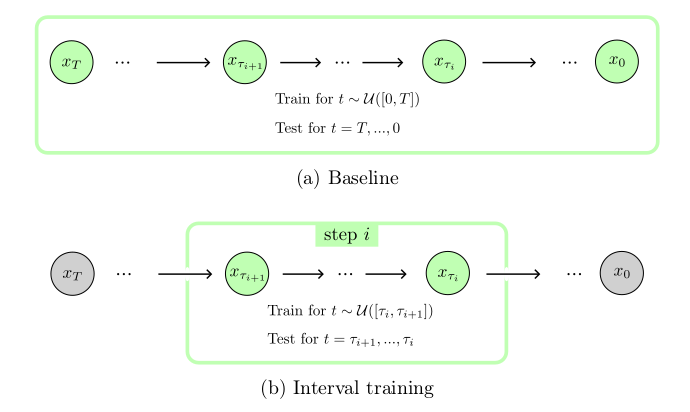
reduce their applicability to videos, and yields unreasonable computational loads. We show that in the case of video inpainting, thanks to the highly auto-similar nature of videos, the training data of a diffusion model can be restricted to the input video and still produce very satisfying results. With this internal learning approach, where the training data is limited to a single video, our lightweight models perform very well with only half a million parameters, in contrast to the very large networks with billions of parameters typically found in the literature. We also introduce a new method for efficient training and inference of diffusion models in the context of internal learning, by splitting the diffusion process into different learning intervals corresponding to different noise levels of the diffusion process.
We show qualitative and quantitative results, demonstrating that our method reaches or exceeds state of the art performance in the case of dynamic textures and complex dynamic backgrounds.